.svg)

AI

Disclaimer:
This article is intended purely for educational purposes in the field of data science. It is not meant to promote or encourage the consumption of alcoholic beverages or intoxicants.
Beer has long been one of the world’s most beloved drinks — and among its many varieties, craft beer holds a special charm. Produced in small batches with a creative touch, each brew often boasts unique flavors and artisanal techniques.
Did you know the craft beer market was valued at $41.07 billion USD in 2018?
And it's projected to reach a whopping $92.80 billion USD by 2025, growing at an impressive 12.35% compound annual growth rate!
But why the surge?
Well, craft beers are limited in production and often hard to find — which ironically makes them even more desirable. Beer lovers are willing to pay a premium for rare, adventurous flavors. Plus, most of these gems are discovered through word of mouth: friend-to-friend recommendations that spark curiosity far better than any ad ever could
Imagine standing frozen in front of a giant fridge packed with craft beers — clueless about what to pick.
Sure, you could ask a store clerk. But wouldn’t it be better to crowdsource opinions from many beer lovers instantly?
Today, while online forums and reviews exist, searching through them manually is tedious and slow.
What if you could just snap a photo of a beer and instantly get reviews, tasting notes, and recommendations?
That's the dream — and that's where Data Science steps in.
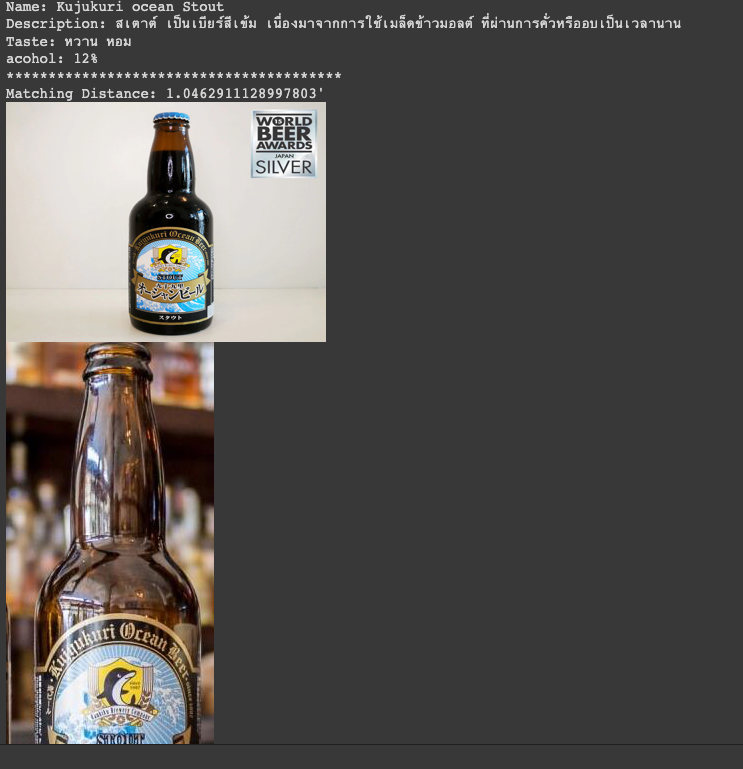
Top Image: A picture uploaded by the user (you, at the fridge).
Bottom Image: Sample matches pulled from our database — imagine them as reviews from other users.
If this idea sounds familiar, you're onto something:
It’s just like Google Image Search!
And the magic behind it?
A technique called One-shot Learning.
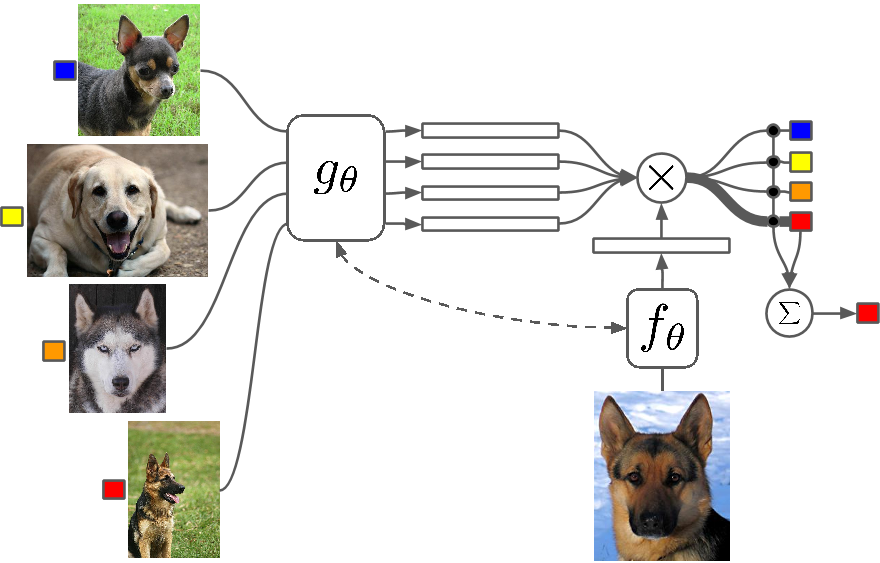
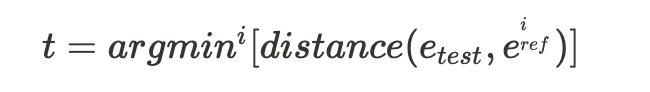
One-shot learning is a machine learning method designed to solve problems where only very few examples are available.
In our case, even if we only have one photo of each craft beer, the system can still recognize and match them.
It works by calculating the distance between feature vectors — the smaller the distance, the better the match. In simple terms: it compares the "fingerprints" of images to find the closest sibling.
You might have seen this concept used in facial recognition systems, where an algorithm must recognize a person even with very few photos.
Usually, they use brute-force vector comparison — fine for small datasets, but with millions of samples? That could take forever.
https://github.com/spotify/annoy
To speed things up, I stumbled upon a game-changing library called Spotify Annoy — the very same tool Spotify uses to power its song recommendation engine.
Annoy (Approximate Nearest Neighbors Oh Yeah) helps by grouping vectors into trees, massively speeding up search queries.
Instead of comparing one-by-one, it creates a clever multi-dimensional vector space (think of it like a colorful 3D map — but actually, it's n-dimensional).
Since humans can only visualize 3 dimensions, imagine the colors in the illustration below represent many more dimensions at play.
But wait — how do we even create these vector fingerprints for our beer images?
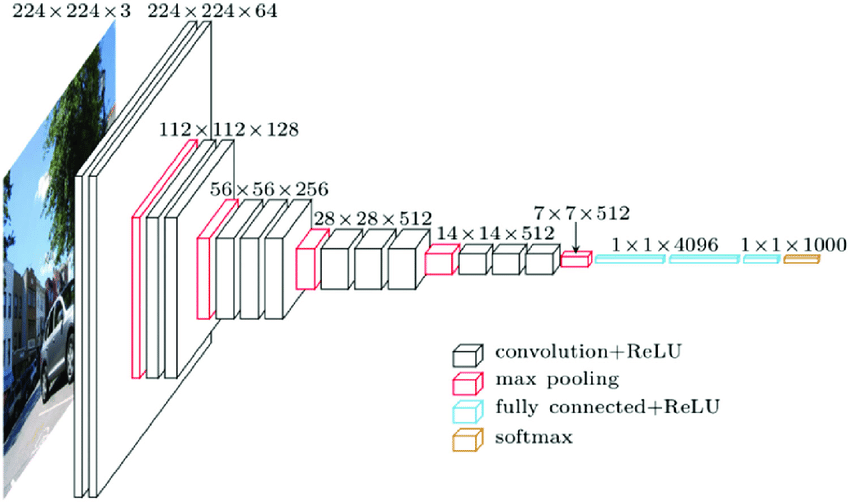
We use Keras and a pre-trained deep learning model!
Here’s the twist:
Instead of using the model to classify images into pre-defined categories (like "dog" or "cat"), we strip away the classification layer and only keep the fully connected layers.
This lets us extract rich feature vectors (of size 4096) — enough to uniquely identify most everyday objects, including our craft beers.
Because Annoy only accepts vectors (not text or extra metadata), we need a way to store both vectors and their corresponding beer info.
For simplicity:
We build an index during the feature extraction process.
We save metadata in a Database.json file.
We configure Annoy to use Angular (Cosine) Similarity for matching, which works beautifully for image comparisons.
With just a smartphone camera, a powerful feature extractor, and a lightning-fast vector search library — finding your next favorite craft beer could be as easy as taking a selfie. Cheers to the fusion of technology and taste!
